JSON är det textformat som har blivit väldigt populärt eftersom det är lätt att skriva och läsa för både människor och maskiner. XML var länge standardsättet att kommunicera med webbtjänster, men med JavaScripts intåg och dess inbyggda stöd för att konvertera mellan textformat och objekt har JSON blivit det absolut vanligaste formatet.
När vi läser eller skriver JSON är det i grund och botten strängar som hanteras. Som utvecklare av webbtjänster i Java behöver vi tolka förfrågningar och skicka svar. Data är ofta hårt typad och lagrad i POJOs (Plain Old Java Objects). Det är en standarduppgift: inget som ska ta för mycket tid att bygga, men som ändå måste fungera pålitligt och stabilt.
Jackson är ett trevligt bibliotek som kan hjälpa oss att lösa utmaningarna med att hantera JSON i Java. Med bara några rader kod kan vi omvandla ett objekt till en sträng redo att skickas över nätverket, eller läsa in en JSON-ström från en fil och omvandla den till ett objekt. Om du har arbetat med Spring Boot tidigare har du troligen redan stött på Jackson, eftersom det är standardbiblioteket för JSON-hantering där.
För att komma igång och arbeta med biblioteket behöver rätt beroenden läggas till Maven i pom.xml. Det går att hitta senaste på MVN Repository. I dag finns det huvudsakligen två versioner 1.x som inte aktivt utvecklas längre och version 2.x som är aktiv version. 3.x är under utveckling och kommer att släppas som ett eget paket (hösten 2025). När du bestämt vilken version du vill använda kan du kopiera rätt beroenden och lägga till dessa till pom.xml.
Kom igång
För att börja arbeta med biblioteket behöver rätt beroenden läggas till i pom.xml. Du hittar de senaste versionerna på MVN Repository.
I dag finns huvudsakligen två versioner:
1.x – inte längre aktivt utvecklad
2.x – den aktuella, aktivt utvecklade versionen
3.x – under utveckling, planeras släppas som eget paket (hösten 2025)
När du har bestämt vilken version du vill använda kan du kopiera beroenderaden och lägga till den i pom.xml:
Med hjälp av Jacksons databindings går det enkelt att konvertera mellan JSON och POJOs.
// Vi använder här en record istället för en klass
public record SuperHero(String name, int hp) { };
public static void testJackson() throws JsonProcessingException {
// Skapa en instans av ObjectMapper
ObjectMapper mapper = new ObjectMapper();
// Skapa en superhjälte med data
SuperHero superMan = new SuperHero(
"Superman",
2000
);
// Konvertera objektet till en JSON-sträng
String superManAsJson = mapper.writeValueAsString(superMan);
// Skriv ut resultatet på skärmen
System.out.println(superManAsJson);
// Skapa en sträng med JSON
String superHeroJson = "{ \"name\" : \"Cat Woman\", " +
"\"hp\" : 2002 }";
// Konvertera stränget till ett objekt
SuperHero catWoman = mapper.readValue(
superHeroJson,
SuperHero.class
);
// Skriv ut resultatet på skärmen
System.out.println(catWoman);
}
JSON som trädstruktur
Ibland har man JSON som behöver läsas in, men det finns ingen motsvarande klass. Då kan man istället läsa in datan som en trädstruktur.
// Konvertera JSON från sträng till nodes
JsonNode jsonNode = mapper.readTree(superHeroJson);
// Hämta ut värdena med hjälp av getters
String name = jsonNode.get("name").asText();
int hp = jsonNode.get("hp").asInt();
// Skriv ut resultatet på skärmen
System.out.println(
"SuperHero was: name = " + name +
" hp = " + hp
);
Hantering av filer
Om datan finns i filer går det bra att använda readValue och writeValue direkt mot en fil.
// Skriv objektet som en JSON-fil
mapper.writeValue(new File("out.json"), superMan);
// Läs in en fil till ett nytt objekt
SuperHero superManFromFile = mapper.readValue(
new File("out.json"),
SuperHero.class
);
Utöver detta går det även enkelt att arbeta med strömmar och byte-arrayer. Detta gör Jackson till ett smidigt och kraftfullt bibliotek.
Anpassning med annoteringar
En annan styrka med Jackson är flexibiliteten i hur konverteringen fungerar – både från objekt till JSON och från JSON till objekt.
Tänk dig att du har ett förbestämt JSON-format som inte matchar med namngivningen i din klass. Med Java-annoteringar kan detta anpassas.
Vi har en klass för skurkar, med name och damage. Dessutom kan skurkar ha hantlangare representerade av en Map<String, Villain>.
public class Villain {
private String name;
private int damage;
private Map<String, Villain> henchmen = new HashMap<>();
// Setters och Getters här
}
Men i vårt JSON-format heter damage istället strength. Dessutom representeras hantlangare som egna attribut. Exempel:
Vi kan lösa detta enkelt genom att arbeta med Jackson annoteringar. Med hjälp av @JsonGetteroch @JsonSetterkan vi styra hur klassen konverteras till och från JSON:
@JsonGetter("strength")
public int getDamage() {
return damage;
}
@JsonSetter("strength")
public void setDamage(int damage) {
this.damage = damage;
}
Damage kommer nu att heta strength både när JSON skapas eller omvandlas till objekt. Detta var enkelt. Nästa steg är att vi behöver hantera vår dörrvakt. Här kan vi använda @JsonAnySetteroch @JsonAnyGetter.
@JsonAnyGetter
public Map<String, Villain> getHenchmen() {
return henchmen;
}
// Notera att sätter tar emot nyckel/värde - inte hela
// map:en.
@JsonAnySetter
public void setHenchmen(String key, Villain villain){
this.henchmen.put(key, villain);
}
På detta sätt kan vi styra exakt hur konverteringen ska gå till. Jacksons ObjectMapper används som tidigare för att konvertera till och från JSON. Du kan hitta hela Villain.java här.
Att koda är i början svårt och komplicerat. Att samtidigt hålla en sammanhållen stil i hur man skriver sin kod, väljer namn och organiserar sin kod kan snabbt bli både svårt och rörigt. Dessutom finns det flera olika stilar att välja mellan. Vad är rätt här, och hur ska man tänka? I denna bloggpost försöker vi ge dig några enkla tips och råd för att ge dig en god start.
Det finns egentligen inga absoluta rätt eller fel – kompilerar det, så är det ju okej. Men det är oftast någon annan som ska underhålla koden du utvecklar, kanske en kollega eller ett framtida du. Därför är det bra att följa en kodningsstil. Många projekt har redan bestämt vilken stil som ska användas, ofta dokumenterat i projektets README.md-fil i roten. Finns det inte, är det en god idé att tillsammans i utvecklingsteamet komma överens om vilken stil som ska följas.
Ett exempel på en stilguide är Googles stilguide för Java. För att hjälpa dig att snabbt komma igång går vi här igenom några av de vanligaste råden från guiden.
Namngivning
I din karriär som programmerare kommer du att behöva namnge en stor mängd olika saker: paket, klasser, metoder, konstanter, parametrar och mer. I början kan det vara svårt att komma på bra namn, och om man är oförsiktig kan det leda till att koden blir svårläst och därmed svårare att underhålla.
Använd endast ASCII-tecken och siffror. I vissa fall kan det vara motiverat att använda _. Det är ofta en fördel att använda engelska även för de identifierare du själv skapar. Annars kan det lätt bli konstigt, eftersom de flesta programmeringsspråk använder engelska nyckelord (som if, for, case, etc.) och de flesta API:er också använder engelska. Det bästa är alltså att hålla sig helt till engelska i koden.
Paket
Paket namnges med enbart gemener (små bokstäver) och siffror. Använd inte understreck, bindestreck eller andra specialtecken.
// Good example
package com.example.myproject;
// Bad example
package com.example.my_project;
Klasser och gränssnitt
Klasser namnges alltid med UpperCamelCase. Skriv ihop orden och börja varje ord med stor bokstav. Om du skapar en testklass bör klassnamnet avslutas med Test. En klass namnges ofta som ett substantiv eller en substantivfras. Gränssnitt (interfaces) namnges på samma sätt, men kan ibland fördelaktigt ha ett verb i namnet.
// Good examples
class Character {}
class ImmutableList {}
interface Readable {}
class ImmutableListTest {}
// Bad examples
class fileWrite {}
Metoder
Metoder namnges med lowerCamelCase: det vill säga första ordet skrivs helt med gemener, och varje nytt ord inleds med stor bokstav. Undvik att beskriva hur metoden är implementerad – använd istället verb som tydligt beskriver vad metoden gör.
Parametrar, variabler och konstanter
Parametrar, variabler och icke-konstanta fält använder lowerCamelCase. Konstanter skrivs med UPPER_SNAKE_CASE, det vill säga versaler och understreck. Loopräknare och andra mycket lokala variabler kan ha enkla namn som t.ex. i.
// Good examples
String firstName = "Martin";
static final int SIZE = 10;
static final String[] NON_EMPTY_CARS_LIST = { "Volvo" };
Filorganisation
Det ska vara lätt att navigera i koden. Klasser bör ligga i egna filer som har samma namn som klassen. Spara alltid dina .java-filer med UTF-8-kodning – detta hanteras automatiskt i de flesta moderna IDE:er.
Följ alltid denna ordning i dina .java-filer:
Eventuell licensinformation
Paketdeklaration
Imports
Exakt en (förstanivå) klass
Separera varje sektion med exakt en tom rad.
Importera aldrig med jokertecken (*), eftersom det gör det svårare att se vilka beroenden koden faktiskt har. Dela upp dina import-satser i två block:
Statiska importer
Vanliga importer
När du implementerar en klass är det bra att hålla en konsekvent struktur:
Börja med klassens fält (members).
Lägg till metoder på rätt plats, inte nödvändigtvis sist.
Alfabetisk ordning är en enkel och tydlig lösning om inget annat anges.
Utformning av kod
Det är inte alltid ett krav att använda måsvingar (krullparenteser) runt kodblock, t.ex. efter en if med endast en sats – men det rekommenderas starkt att alltid göra det, för att öka läsbarheten och minska risken för misstag.
Tomma block får ligga på samma rad, men endast om det är ett ensamt block.
Använd 2 mellanslag som indrag – inte tabbtecken.
Skriv endast en sats per rad.
Att linjera deklarationer eller satser är tillåtet, men inget krav – sådana justeringar kan snabbt bli fel vid ändringar.
Det finns naturligtvis mycket mer att säga om Googles kodstil och vad som är god praxis när man skriver kod. Men som ny utvecklare är detta en god start. Använd en kodstil både när du skriver kod själv och när du kodgranskar eller parprogrammerar.
Det kan ta lite längre tid i början att få koden att se ”rätt” ut – men tiden du sparar i framtiden, när du eller någon annan ska göra ändringar, är ofta betydligt större.
Som programmerare kommer du att komma i kontakt med flera olika mönster som är tänkta att lösa vissa specifika problem. Model-View-Controller, eller MVC, är ett vanligt programmeringsmönster som används både i frontend- och backendapplikationer. Det finns många fördelar med mönster, vilket gör det bra att skaffa sig grundläggande förståelse för de vanligare mönstren.
Vanliga fördelar är att man slipper fundera ut en lösning varje gång man har ett problem. Mönstret finns där som en vägledning och guide för hur man kan strukturera lösningen. Detta gör det inte bara snabbare och enklare att skriva kod från början, utan det underlättar också för nya programmerare som kommer in i ett projekt. På samma sätt underlättar det vid kommunikation runt en specifik lösning eftersom alla utvecklare använder samma terminologi i projektet.
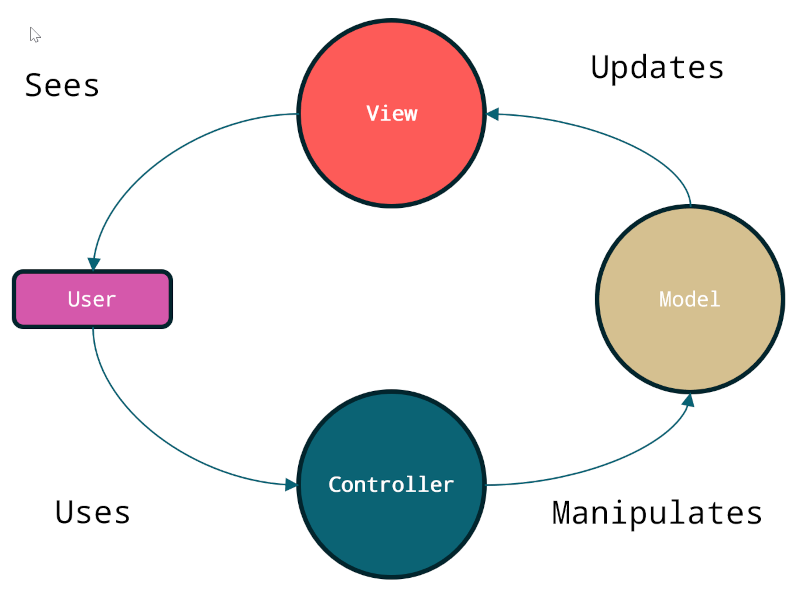
MVC är ett väldigt vanligt mönster som hjälper till vid skapandet av användargränssnitt. Inom JAVA-utveckling är det ett mönster som ofta används för att bygga desktopapplikationer eller webbapplikationer – gemensamt är att de har data (Model) som användaren tittar på (View) och kan göra saker med (Controller).
Blockdiagram över Model-View-Controller
De olika komponenterna i mönstret har olika ansvar och gör olika saker.
Model används för att representera datan. Det är en datastruktur som är helt oberoende av både view och controller. Modellen ansvarar för att hantera data, logik och affärsregler i applikationen. Det är vanligt att en modell är speglad av en bestående lagring som t.ex. en tabell i databasen.
View är en representation i användargränssnittet. Många gånger behövs det flera vyer till samma modell, t.ex. kan det vara olika vyer som ansvarar för visnings, skapande och redigerings gränssnitt för samma modell.
Controller är komponenten som hanterar händelser i användargränsnittet och gör om dem till kommnadon för modellen. Det kan finnas flera kontrollers som arbetar mot samma modell – det är vanligt att en vy är kopplad till en kontroller men det förekommer att flera vyer använder samma kontroller.
Controllers i blått, Models i grönt och Views i gult
När användaren besöker sidan kommer hen till en controller som sedan hämtar data från modellen och en vy renderas. Användaren kan sedan interagera med gränssnittet, vilket i sin tur gör att metoder i controllern anropas. Hur de olika komponenterna faktiskt implementeras beror på vilken typ av applikation som byggs och vilka ramverk som används.
PHP är fortfarande år 2025 ett mycket populärt programmeringsspråk för att bygga webbapplikationer. Det är lättillgängligt, enkelt att hosta och relativt lätt att lära sig. Den största utmaningen som utvecklare är ofta att få en bra utvecklingsmiljö på plats. Ett vanligt tillvägagångssätt är att installera en färdigpaketerad miljö såsom MAMP, XAMPP eller WAMP. Jag är personligen inte särskilt förtjust i dessa lösningar eftersom de begränsar vilka versioner av de olika komponenterna du kan använda. Dessutom belastar dessa serverprogram datorn onödigt mycket.
Alternativet är att installera webbserver, MySQL och PHP var för sig och därefter konfigurera miljön manuellt. Det har vissa fördelar, såsom att hela PHP:s verktygskedja blir tillgänglig. Nackdelen är att det rör sig om flera program som kräver uppdatering och underhåll. Därför är jag inte heller helt nöjd med detta alternativ.
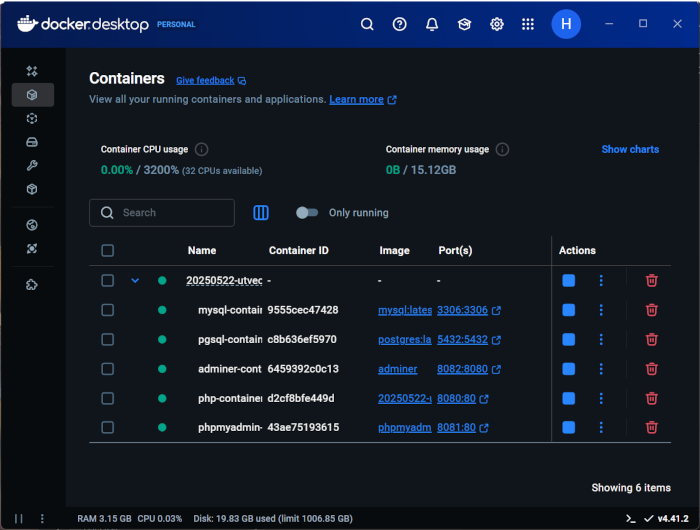
Ofta faller jag tillbaka till att använda Docker och köra applikationerna i containrar. Det gör det enkelt att skapa en miljö, uppdatera den och återskapa exakt samma miljö på en annan dator. Det enda som behöver installeras är Docker. Det är inte särskilt svårt, och med Docker följer dessutom Docker Compose, som är ett fantastiskt verktyg för att starta flera containrar samtidigt.
Docker desktop som har ett projekt med 5 körande containers
Innan vi fortsätter bör vi förklara vad avbildningar och containrar är. En avbildning är en mall för hur en virtuell maskin ska se ut – med operativsystem och alla installerade applikationer. En container är en körande instans av en avbildning. Det finns avbildningar för nästan alla applikationer du kan tänkas vilja köra. Ibland behöver en avbildning anpassas, vilket görs genom att skapa en ny avbildning som ärver från en befintlig version.
En avbildning kan skapas med hjälp av en Dockerfile.
# php.dockerfile
# Use php:8.2-apache as base image
FROM php:8.2-apache
# Install your extensions
# Add mysqli
RUN docker-php-ext-install mysqli
# Install pdo if you need to use PHP PDO
RUN docker-php-ext-install pdo pdo_mysql
# Run docker-php-ext-enable command to activate mysqli
RUN docker-php-ext-enable mysqli
I detta exempel skapar vi en egen avbildning baserad på PHP:s officiella avbildning. I denna finns Linux och en Apache-webbserver, men den saknar stöd för MySQL. Anpassningen innebär att vi installerar de komponenter som behövs (raderna 7 och 9) och till sist aktiverar vi den modul PHP behöver för att kommunicera med en MySQL-databas.
Vi kan bygga avbildningen med kommandot docker build. Därefter startar vi en container från avbildningen med kommandot docker start. Då är en enkel miljö igång men vi vill även ha en databas och några andra komponenter. Dessa kan också köras i Docker. När vi behöver flera avbildningar blir det snabbt krångligt att starta alla containrar manuellt. Här kommer Docker Compose in i bilden. Det läser in en annan fil, docker-compose.yml, och startar samt konfigurerar flera containrar åt oss. Enklare och smidigare. Låt oss titta på följande docker-compose.yml-fil:
Här definierar vi tre tjänster: PHP (rad 2-12), MySQL (rad 14-28) och phpMyAdmin (rad 30-41). Varje tjänst startas som en separat container. Vi definierar även volymer för datalagring och ett nätverk som containrarna kan använda för att kommunicera med varandra.
Låt oss titta närmare på en tjänstedefinition. Först specificeras vilken avbildning som ska användas. Det kan antingen vara en specifik avbildning, som mysql:latest, eller en build-sektion som beskriver hur en anpassad avbildning ska byggas – vilket vi gör med PHP.
Varje container behöver ett unikt namn. Man kan skapa flera instanser av samma avbildning, men varje instans måste ha ett unikt namn. Ofta behöver programvaran i containern konfigureras, och då är miljövariabler ett smidigt sätt. I MySQL (rad 19–22) och phpMyAdmin (rad 34–35) används miljövariabler som kan justeras vid behov. Här anges t.ex. vilka uppgifter som behövs för att ansluta till databasen.
Data i en container är inte beständig. Det är ett problem vid utveckling eftersom man vill kunna spara det man skapat. Genom att montera volymer i containern kan en yta utanför containern göras tillgänglig. För PHP (rad 8) monterar vi src-katalogen mot /var/www/html i containern (om katalogen inte finns kommer den att skapas). Då kan vi arbeta med filer i src och köra dem direkt via containern. Databasen använder en Docker-volym (raderna 24 samt 43–44), vilket är vanligt för binärdata som måste sparas.
Man kan bestämma vilka portar containrar ska exponera. För PHP mappas port 8080 på värddatorn mot port 80 i containern (rad 10). Det gör att vi kan surfa till localhost:8080 och komma åt webbservern. För databasen görs localhost:3306 tillgänglig (rad 26) och phpMyAdmin exponeras via port 8081 (rad 37). phpMyAdmin är ett populärt verktyg för att administrera MySQL-databaser.
Till sist ser vi att alla tjänster kopplas till nätverket app-network, vilket gör att de kan kommunicera med varandra. Det innebär t.ex. att ett PHP-script i PHP-containern kan ansluta till MySQL-containern.
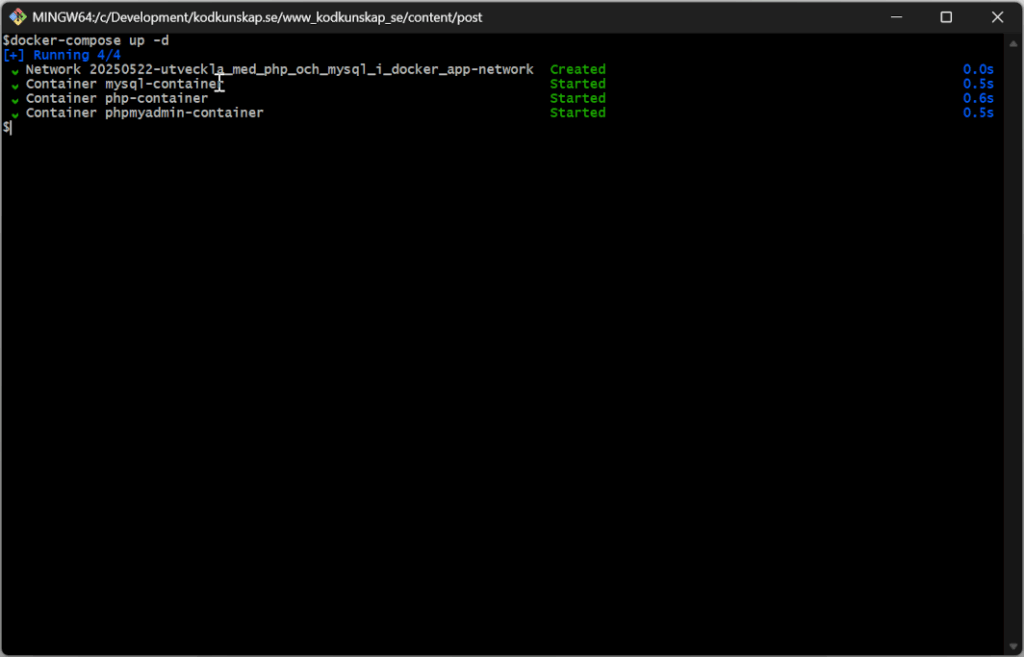
Uppstart av flera containrar går fort
När konfigurationen är på plats kan du köra docker-compose up -d för att starta tjänsterna. Första gången tar det en stund eftersom avbildningarna laddas ner. Därefter går uppstarter snabbt. Du kan stoppa alla tjänster med kommandot docker-compose down eller via Docker Desktop.
Nu är allt klart. När tjänsterna är igång jobbar du med din PHP-kod i src-katalogen. Webbläsaren svarar på localhost:8080 och phpMyAdmin finns på localhost:8081.
Lycka till med din utveckling!
Nedladdningar
Du kan ladda ner mina filer här om du inte vill klipp och klistra:
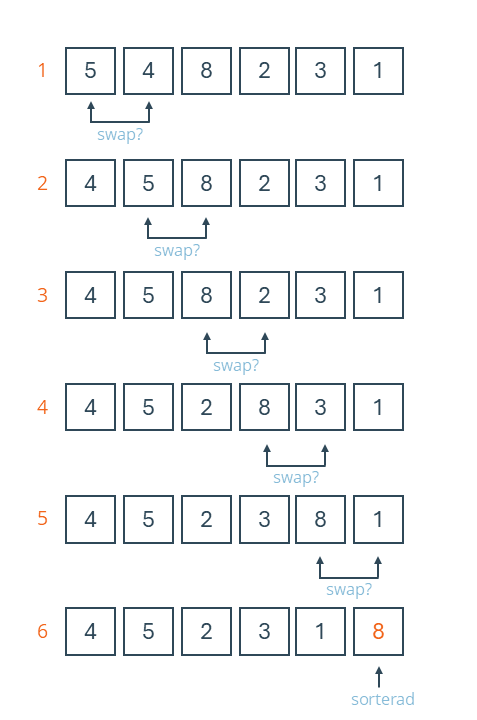
Bubble Sort är en av de mest välkända sorteringsalgoritmerna. Den har blivit populär eftersom den är enkel att förstå och dessutom en utmärkt introduktion till analys av algoritmer och datastrukturer. Algoritmen beskrevs för första gången av Edward Harry Friend i den vetenskapliga artikeln “Sorting on Electronic Computer Systems” från 1956.
Algoritmen arbetar på en array där den jämför två intilliggande element. Om det första elementet innehåller ett värde som är större än det andra, byter de plats. Sedan går algoritmen vidare och jämför det andra och tredje elementet. På detta sätt skjuts de större värdena successivt mot slutet av arrayen. När hela arrayen har genomgåtts kommer det största elementet att finnas längst till höger. Därefter börjar algoritmen om från början. Listan genomlöps lika många gånger som det finns element för att garantera att alla har hamnat på rätt plats.
Illustation av Bubble Sort
Algoritmen har en tidskomplexitet på O(n2), vilket innebär att tiden det tar att sortera växer kvadratiskt i förhållande till mängden data. Med andra ord: om man dubblar datamängden fyrdubblas arbetet som krävs för att sortera den. Därför blir algoritmen snabbt oanvändbar för stora datamängder. Minneskomplexiteten är O(1) eftersom algoritmen sorterar elementen på plats utan att använda extra minne.
Det finns vissa sätt att optimera algoritmen. Man kan till exempel successivt minska hur långt in i arrayen som sorteringen sker, eftersom man vet att elementen i slutet redan är på rätt plats. Detta påverkar dock inte algoritmens Big-O-klassificering.
Exempel implementation i C++
Att implementera Bubble Sort i C++ är en bra övning – både för att förstå algoritmens funktion och för att träna sina C++-kunskaper. Nedan finns ett exempel på en implementation i C++. Datatypen vector liknar en vanlig array, men har inbyggt stöd för att ändra storlek.
#include <vector>
void bubbleSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 0; i < n - 1; ++i) {
for (int j = 0; j < n - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
}
}
}
}
Exempel implementation i Java
Bubble Sort är inte beroende av ett specifikt programmeringsspråk och går därför utmärkt att implementera även i Java. Tänk på att List är ett interface i Java. För att sorteringen ska vara effektiv är ArrayList den bästa datatypen att använda med denna sorteringsalgoritm.
import java.util.List;
import java.util.Collections;
public class BubbleSorter {
public static void bubbleSort(List<Integer> arr) {
int n = arr.size();
for (int i = 0; i < n - 1; ++i) {
for (int j = 0; j < n - i - 1; ++j) {
if (arr.get(j) > arr.get(j + 1)) {
Collections.swap(arr, j, j + 1);
}
}
}
}
}
PHP är fortfarande år 2025 ett mycket populärt programmeringsspråk för att bygga webbapplikationer. Det är lättillgängligt, enkelt att hosta och…
Kontakt
Kodkunskap är en plattform för alla programmerare – från nybörjare till erfarna utvecklare – som vill fördjupa sina kunskaper, dela insikter och växa tillsammans inom kodning och teknik.